



1 Introduction
From the 2000’s we had to study a new concept in management sciences. It was ‘Business Intelligence’ (BI). Krauth () summarized the actual information about Business Intelligence and also forecasted the expected development and changes of BI for the next ten years. One of the priorities changes he emphasized was that ‘Technologies providing business intelligence will leave the corporate framework and move on a much wider scale to serve the growing demands of organizations and individuals for accurate, substantial and comprehensible information.’
After ten years we saw that the demand was actually raised in the leaders of small and medium enterprises also for the dissolution of business intelligence, furthermore there are several so-called self-service business intelligence solutions we should use to satisfy this demand. From the 2010s we could see that the basic technology of business informatics the online analytical processing (OLAP) was released in scientific research also, mainly in processing measured data.
In the 2000s business environment – mainly in small and medium enterprises – unfortunately we saw that neither the economists nor the IT staff of these small firms could work with this BI-solutions (softwares). The reason for the problem is not in technical difficulties but in acquiring the right way of thinking to model the function of their own firm, define correctly the information requirement of management (conceptual modeling) and translate it to a logical model.
We participated in a data warehouse projects where we realized that our ‘corporate bus matrix’ contained about 80–120 indicators with nearly 200 dimensions (dimensional attributes), therefore we started to work on the early stenography to formalize the management question ().
2 Related Works
It is an often-mentioned problem today in the literature that there is no standardized or widely agreed method for implementing the conceptual model (; ; ). Furthermore, it is a good practice to try to follow the classical design steps of database systems () in the design of the data warehouse (conceptual model->logical model->physical model->implementation), but opinions differ in the literature which should be the right order of the steps, furthermore, there is a lot of overlap. Mainly conceptual and logical modeling are often mixed with each other or their borders are blurred, however Halassy clearly defined the levels of database planning, furthermore he proved that these levels must be separated from each other ().
According to the method presented by us, the conceptual model is nothing more than a set of formalized leadership questions. A management question can already be seen as part of an OLAP data cube, and OLAP cubes can be built from subsets of management questions. The question is to optimize their number and distribution. That is, how many cubes do we have to build and how many questions can be answered. While the former is a matter of financial concern for customers, the latter is about the efficiency of the information system.
As regards data warehouses as information systems, the question of efficiency is most of all the above-mentioned two aspects (cost and amount of information that can be extracted). Di Tria, Lefons, & Tangorra () tested design methodologies and carried out for cost-effectiveness analysis. They have set up their framework and metrics to implement this analysis. The classic approaches of data warehouse design can be sorted into two sets: data driven methods and requirement driven methods. Both have advantages and limitations also (). For example, the requirement driven approach leads such multidimensional schemas that usually results in one data cube that answer only one question of the management. The main problem with the multidimensional schemas of the other approach is the big number of the potential questions which cause data lakes that become data swamps. We consider a cuboid as a base of a potential management question. The problem is: what is the minimal (optimal cost) number of cuboids? These problems with both approaches lead to the birth of several so-called hybrid modeling methods to design data warehouses. Di Tria, Lefons, & Tangorra () identified the criteria based on the literature to evaluate these hybrid methods. They used the 4 common and main criteria that is necessary to evaluate a data warehouse designing methodology. These are: Correctness, Completeness, Minimality and Understandability (). Furthermore, based on the literature they defined metrics to the evaluation of costs and benefits, specially the ‘Metrics for schema quality’ and the ‘Metrics for design effort’. Then they compare six hybrid methods based on this framework:
- Graph-based Hybrid Multidimensional model (referred to as GrHyMM),
- UML for Data Warehouse (referred to as UMLDW),
- Multidimensional Design by Example (referred to as MDBE),
- Phipps&Davis Methodology (referred to as PDM),
- Goal-oriented Requirement Analysis for Data Warehouse Design (referred to as GRAnD),
- Goal/Question/Metric-based Methodology (referred to as GQM).
Based on Di Tria, Lefons, & Tangorra () in Table 1 we present the steps of the six methodologies above and the features or results of the certain steps, extended with our Visualized Management Question-based Design methodology (referred to as VMQD*).
Table 1
Steps of the six methodologies.
| GrHyMM | UMLDW | MDBE | PDM | GRAnD | GQM | VMQD* | |
|---|---|---|---|---|---|---|---|
| Requirement Analysis | goals, tasks | goals, tasks | queries in SQL | queries in SQL | goals, decisions | goals, questions, metrics | visualized questions, metrics, dimensionality |
| Minimal Granularity | minimally detailed metrics | ||||||
| Ideal Schema | ideal facts, ideal dimensions | ideal facts, ideal dimensions | |||||
| Source Analysis | independent, source system schema | independent, CWM | independent | independent | independent | independent, potential schema | potential transactions, attributes, partly dependent, |
| Integration | potential schema vs.ideal schema | potential schema vs.ideal schema | |||||
| Reconciliation | DB integrity | consistent UML multidimensional schema | DB integrity | ||||
| Multidimensional Modeling | facts, attribute tree for facts, remodeling | cubes, dimensions, hierarchies, measures | dimensions and facts from tables | Date dimension and Attribute dimensions for factsMeER | Derived from requirement analysis schemas | MeER | |
| Schema Selection | MeER related to questions | ||||||
| Manual Refinement | modified automatically generated schema | ||||||
Our Visualized Management Question-based Design methodology is closest to GQM in the steps, but there are some differences.
- Requirement Analysis. We collect questions with metrics and dimensionality of the problem also in this phase with the required visualizations from the decision makers via interviews. Then we formalize these specifications with our special structured stenography that is based on the terminology corresponding to the current problem. The output of this step is a set of formalized questions.
- Deriving minimal granularity. Based on the set of formalized questions we specify the required minimal granularity for every indicator. The output of this step is the set of indicators with minimally detailed dimensions.
- Deriving ideal schemata. We map the dimensional attributes and values to keys, produce the initial conceptual schemata. The output of this step contains ideal dimensions (keys, attributes and hierarchies) and ideal facts (with dimension keys for join), independently from the sources.
- Source Analysis. The main question of this step is: What kind of transactions can we get them from? We decompose ideal facts into potential elementary transactional attributes and identify them in the source systems. The output of this step is the derived potential schemata.
- Integration. Ideal schemata from the requirement analysis are compared with potential star schemata. Match occurs, when the two schemata contain the same fact, and, both have the same dimensionality in the same granularity level. In this step we define required transformations and calculate fact tables and common dimensions with attributes.
- Multidimensional modeling. We build the cube(s) with dimensions, dimension hierarchies and measures.
We used the Di Tria, Lefons, & Tangorra () notation to visualize the framework of our methodology for better comparison (Figure 1).
Framework of VMQD.
Every question of the management is a visualization of aggregated indicator(s) detailed with dimensional attribute(s). So, we must formalize these questions of the management.
The formalisation has to cover:
- aggregations (aggregate functions)
i.e. sum, min, max, average, count, median, modus, correlation, etc.; - indicators with unit
i.e. Price$, Quantitypcs, Weightkg, etc.; - visualization
i.e. table, line chart, map, network graphs, population pyramid, etc.; - attributes
i.e. Gender, Product name, City, Order date, etc.; - attribute aggregation
i.e. sum, min, max, average, rate, distribution, etc.; - dimensions
i.e. Person, Product, Geography, Date, etc.; - dimension hierarchies
i.e. Product->Product category, City->County->Country->Continent
The structure and syntax of the formalization is:

3 Methodology of formalization of conceptual design
In the following paragraph we would like to explain our methodology.
- In the phase of requirement analysis, we collect and formalize management questions. The question and description are defined in a textual and formal way. The ‘manager’ is the person for whom the system provides information. As a result, she expects to see a data-visualization report appearing on different dashboards. The reports and dashboards need to be configured according to the requirements of access rights (what kind of level managers can access the statements).
In the requirement analysis, we ‘analyse’ the management question based on the following considerations in Table 2:
What is the indicator? In which aggregation? What is the unit? Which visualization we want to see? in Which detail(s)? Is there a slicer?
Formally: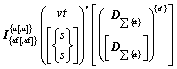
This formal definition is related to one diagram. Several different visualizations need to arise from the leader on a question related to the requirement specification, so many formal descriptions are made in this section. - Deriving the minimum granularity for each indicator. Determine the indicators in the management question and determine the required minimum granularity (dimension and key), where:
- I{u} the indicator I with u unit(s) in the upper right index
- D{dk} dimension D with dimension key dk in the lower right index

- When we derive an ideal schemata, we produce fact tables for the indicators specified in the minimum granularity and optimizing the number of fact sheets. The properties are grouped into dimensions and hierarchies. Each dimension must have a dimension key (see relational data model), where:
- I{u} the indicator I with u unit(s) in the upper right index
- D{dk} dimension D with dimension key dk in the lower right index
- D{a} dimension D with attribute a in the lower right index
- D{i} dimension D with indicator i in the lower right index
- D{dhk} dimension D with dimension hierarchy key dhk in the lower right index, when hierarchy levels are stored in separate tables
 , or
, or  depending on whether the given fact table contains one or more indicators.
depending on whether the given fact table contains one or more indicators.
Dimension table formally:
During optimization we can notice one of the following cases in Table 3:- Different indicators with the same dimensionality and granularity can be grouped into one fact table.
- Different indicators could be similar when they have the same dimensionality but diverging granularity, so we examine whether they can be produced from one another.
- Dimensionality of one indicator is a proper subset of the dimensionality of the other indicator, so the other indicator dimensionality will be the minimum required.
- We will evaluate the available data during the source analysis. Source system can be transaction-oriented or analysis-oriented.
- The Transaction-Oriented Source System (OLTP) is characterized by a relational data model
 and
and 
where:- E( ) E entity in the source system,
- E{pk}pk primary key of E entity
- E{a}a attribute of E entity
- E{fk}fk foreign key of E entity
- R( ) R relation, transaction between different entities, with the relational attributes
- R{a}a attribute of R relation
- In the case of an Analysis-Oriented Source System (OLAP), the multidimensional relational model is typical.
Fact tables formally: , or
, or 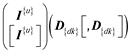 depending on whether the given fact table contains one or more indicators.
depending on whether the given fact table contains one or more indicators.
Dimension table formally: , wehere:
, wehere:- I{u} the indicator I with u unit(s) in the upper right index
- D{dk} dimension D with dimension key dk in the lower right index
- D{a} dimension D with attribute a in the lower right index
- D{i} dimension D with indicator i in the lower right index
- D{dhk} dimension D with dimension hierarchy key dhk in the lower right index, when hierarchy levels are stored in separate tables
- The Transaction-Oriented Source System (OLTP) is characterized by a relational data model
- During integration, we coordinate the ideal data model with the available source system data. Describe the requirements that include attributes, dimension keys, and additional indicators to use. We design the data loading (ETL/ELT) process in Table 4.
Table 2
Management question analysis.
| Indicator |

| the indicator I to be produced with u unit(s) in the upper right index and af aggregate function(s) in the bottom right index, |
| unit(s) | ||
| aggregate function(s) | ||
| visualization |

| the v visualization with the type vt (table, line diagram, bar graph, etc. …) and optional s slicers (values can be D{a} dimensional attribute, D{v} subset of concrete values, or a D{a} dimensional attribute in the d detail of another I indicator on the same dashboard) |
| slicer(s) | ||
| detail(s) |

|
d details with D{a} dimensional attribue(s), with optional  aggregation. d values e.g.: row, column, category, y indicator aggregation. d values e.g.: row, column, category, y indicator |
Table 3
Optimizations’ notations.

| Combining indicators I1 and I2 with the same dimensionality. We create the Descartes multiplier of the two indicators. |
 | The value of the indicator I can be obtained by summing through dimension D (roll up) with the aggregate function in the lower left index of I. Calculating the aggregation from D{dk} at the bottom of the Summa symbol to the level at the top of the Summa sign (all or D{dhk} hierarchy level, leaving the original key. This is referred to as  . . |

| A and B are dimensions of indicators I1 and I2 and I1 is proper subset of I2. |
Table 4
Data loadings’ transformation notations.
 | The value of the indicator I can be obtained by summing through D dimension (roll up) with the aggregate function in the lower left index of I. This is an aggregation is from D{dk} at the bottom of the Summa symbol to the level at the top of the Summa Sign (all or D{dhk} hierarchy level, leaving the original key. This is referred to as . |

| Deduplicate the values of D dimensions’ D{dk}. key. Summarize the indicator with the af aggregate function in the lower left index, while leaving the first element of attribute values. |

| Expand the dimensionality of indicator I. The Descartes multiplier of the original indicator with the dimension to be expanded. |
 | Pivoting I indicator values through D{a} dimensional attribute. We create several new indicators corresponding to the occurrence values of the attribute. |

| Combining I1 I2 indicators with the same dimensionality. We create the Descartes multiplier of the two indicators. |
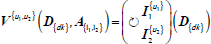 | Unpivoting I1 I2 indicators with the same dimensionality into V indicator values and A attribute set with the indicators’ name |

| The sum of pivoted  indicator values along the occurrence values of D{a} attribute. indicator values along the occurrence values of D{a} attribute. |
In the data loading process, extracting, transforming, and loading only those keys, attributes, and indicators from the source system to the data warehouse that we need.
During the transformation of data, two types of data loading processes can be discussed:
- During ETL (Extract, Transform, Load) process the various data manipulations carried out after extracting the data from the source system are typically in an intermediate system (Staging Area) and then transferred to the data warehouse. Intermediate use of complex multi-step data manipulations (transform) is needed, for simpler systems it is worth thinking about using it as it can serve more data warehouses with intermediate data than a commonly used general date dimension, geographical dimension, organizational dimension (enterprise data lake).
The transformations can be simple, then the indicators are loaded from one source system relation, and the dimensions are also derived from a single source system.


The transformations may be more complicated when the values of the indicators are loaded from several relations’ attributes or from several different source systems. This also occurs with the indicators of dimension.
- During ELT (Extract, Load, Transform) process the various data manipulations take place after the data is extracted from the source system and loaded into the data warehouse.
When we formalize a business question, the method is pure requirement-driven. We do not bother with data-driven approach at this stage. We bother with it after we have collected and formalized and modelled all the questions, and the required data model is generated, then we examine the questions through the data-driven approach also. At this point we examine how the formalized elements of the questions are stored in the source systems. If we can produce them in the required granularity (or more detailed) then we optimize them (for example with the use of some kind of aggregation function) to the ETL/ELT (Extract-Transform-Load/Extract-Load-Transform) processes.
4 Research data processing example (Collecting and processing fitness tracker data)
The relationship between physical inactivity and some chronic health conditions is a widely researched area but further efforts are needed to assist people to adopt healthier lifestyles (). Using wearable activity trackers can be a promising opportunity for individuals to improve lifestyle behaviour (). There are several studies in this area, mainly from the lifestyle behaviour and health approach (; ; ). Our research does not examine activity trackers from the aspect of health, we want to present the way that we can process data with OLAP technology we collected with a very simple device. If an end user who wants to know his own activity by using such an activity tracker, usually he downloads a software that processes his data every day and informs him. But if we plan a wide research where we want to collect several persons’ data, and we want to recognize trends and patterns in the behaviour of the society, it could be a useful approach if we plan a data cube with OLAP approach. With our hybrid design methodology, we get metadata from the dimensions and attributes, so if we extract our data into a dataset, we get the formal description of the structure of our dataset also, in order to share and compare it to other similar researches.
Our research investigated the physical activity of university students using fitness tracker. Participants in the pilot test had to meet several criteria. Participants had to wear the device with normal living conditions for 90 consecutive days, which simulated the normal living conditions of most students. An important element of the long-term pilot test is that it can represent the full range of normal people’s activities in a real environment. Each participant was informed on the most important information about the device and the potential for managing possible sources of error. The battery of the bracelet was recharged by the users every 20 days, depending on the use, whereby the data was collected at the same time. The data was sent by the users for one week on a daily basis and then at the charges mentioned above. This level of data supply has served to reduce the potential loss of data. We informed the students about the study and all the participants provided informed consent in compliance with the principles of the Declaration of Helsinki () and the new GDPR (). The study was approved by the Regional Ethics Board (DE RKEB/IKEB: 4843-2017) at the Clinical Canter of the University of Debrecen.
Collected bracelets’ data are processed using OLAP technology. We use the following hybrid design methodology and formal descriptive techniques to design, implement, and document the operations related to the information system (Research Data Warehouse) that we produce.
4.1 Requirement analysis
Question1 formally in Table 5: The students’ daily activity by daily steps intensity categories in March:
Table 5
Question1 analysis.
| Indicator | how many days completed (activity) |

| Activity{day} |
| unit(s) | day | ||
| aggregate function(s) | how many (sum) | ||
| visualization | table |

|

|
| slicer(s) | March | ||
| detail(s) | student |

|

|
| daily step category |

|

| |

It shows how many days were completed by the students in March by daily step categories.
The ‘daily step categories’ naturally require a detailed discussion during the requirement analysis and at the same time predicts a clustering task in the integration phase.
Question 2 formally in Table 6: Students’ average daily activity in March by category and gender:
Table 6
Question2 analysis.
| Indicator | averagely completed days |

|

|
| unit(s) | day | ||
| aggregate function(s) | average | ||
| visualization | table |

|

|
| slicer(s) | March | ||
| detail(s) | gender |

|

|
| daily step category |

|

| |
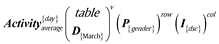
It shows the students’ averagely completed days in March by daily step categories and gender.
The term ‘students’ and ‘daily’ refers to the maximal details of the data average that we can deal with in the minimal granularity, optimal data model or in the integration phase.
Question 3 formally in Table 7: Average daily steps of men, women and all by the day of the week in March:
Table 7
Question3 analysis.
| Indicator | Daily steps |

|

|
| unit(s) | steps | ||
| aggregate function(s) | average | ||
| visualization | radar chart |
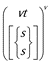
|
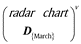
|
| slicer(s) | March | ||
| detail(s) | day of the week |

|
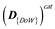
|
| men, women, all |

|

| |
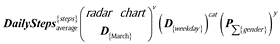
It shows a comparison of mens’, womens’ and combined average daily number of steps in March, in the days of the week.
4.2 Minimum granularity for each indicator
We define attributes for values and keys for dimensional attributes in the questions.

March is month value of Date dimension (D{March}) so the related dimension key should be MonthKey (D{MK})
Neptun ID is an attribute of Person dimension (P{stud}) so the related dimension key should be PersonKey (P{PK}).
Daily step category is an attribute of activity Intensity dimension (I{dsc}), so the dimension key should be IntensityKey (I{IK}).

March is month value of Date dimension (D{March}) so the related dimension key should be MonthKey (D{MK})
Gender is an attribute of Person dimension (P{gender}) so the possible dimension key should be PersonKey (P{PK}) or GenderKey (P{GK}), the minimum granularity is GenderKey (P{GK}).
Daily step category is an attribute of activity Intensity dimension (I{dsc}), so the dimension key should be IntensityKey (I{IK}).
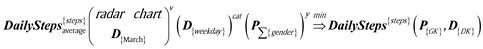
March is month value of Date dimension (D{March}) and weekday is an attribute of Date dimension (D{weekday}) so the related dimension key should be MonthKey (D{MK}) and DayofWeek (D{DoW}), so the common dimension key for both is DateKey (D{DK}).
Gender is an attribute of Person dimension (P{gender}) so the possible dimension key should be PersonKey (P{PK}) or GenderKey (P{GK}), the minimum granularity is GenderKey (P{GK}).
The following indicators with the minimal required granularity should be the base to answers each question we have:

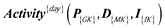
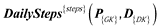
4.3 Ideal schemata for OLAP system
In this step we determine which indicators can be stored in a common fact table.
During optimization, we can see which indicators are similar and can be produced from one another. In this case activity indicator detailed by GenderKey (GK) can be generated from the activity indicator detailed by PersonKey (PK). This means that we have already managed to optimize the number of indicators we are building.


The average DailySteps indicator must break down into gender variants and the aggregated.

Next step is to place indicators into fact tables. Indicators with the same dimensionality and granularity are placed into a common fact table. In this case these are the daily activity and the daily steps fact tables.
ftDailyActivity: Daily activity fact table

ftDailySteps: Daily steps fact table

Dimensional attributes and values in questions and dimensional keys in the minimal and ideal data model must be organized into dimensions. In this step we specify the Dimension->Key-Attribute-Indicator->Value structures, also the required dimension hierarchies with hierarchy-keys. We have three dimensions (Person, Date, Intensity) in our ideal data model in the following structure:
-
P: Person (dimPerson)
- PersonKey (P{PK}): HASH of students’ identifier
- Student (P{stud}): students’ identifier (eliminated, because of GDPR)
- GenderKey (P{GK}): unique identifier, values {1, 2} (eliminated, when we unfold the dimension hierarchy)
- Gender (P{gender}): gender of students, values {Male, Female}
-
D: Date (dimDate)
- DateKey (D{DK}): year, month, day serial number with leading zero, composition {yyyy}{mm}{dd}
- Day of Week (D{DoW}): unique identifier, serial number of weekdays {1..7} (eliminated, when we partly unfold the dimension hierarchy)
- Weekday (D{weekday}): {1 – Monday, 2 – Tuesday, …, 7 – Sunday}
- MonthKey (D{MK}): year, month serial number with leading zero, composition {yyyy}{mm}
-
DM: DateMonth (dimDateMonth)
- MonthKey (DM{MK}): year, month serial number with leading zero, composition {yyyy}{mm}
- Month (DM{month}): month name, values {January, February, …, December}
-
I: Intensity (dimIntensity): Categories of daily activity of students.
- IntensityKey (I{IK}): {0..5}
- Daily Step Category (I{dsc}):
- 0 – Basal activity
- 1 – Limited activity
- 2 – Low activity
- 3 – Somewhat active
- 4 – Active
- 5 – Highly active
4.4 Source analysis
In this phase we discover the data of the source systems driven by the facts and dimensions specified in the ideal data model.
4.4.1 Activity tracker data
SiOS (S{steps}, S{timestamp}, S{date}, S{10min},) Emails sent via email from iPhone, the name of the file contains the student’s Neptun identifier and the date of submission in the S{NID}–S{sd} structure.
SA (S{cumulative steps}, S{timestamp}, S{date}, S{min},) Emails sent via email from Android phone, the name of the file contains the student’s Neptun identifier and the date of submission in the S{NID}–S{sd} structure.
-
S: Steps (noted as rSteps) with the following attributes and values:
- Date (S{date}): {year}.{month}.{day}
- DateKey (S{DK}): {year}{month}{day}
- 10mins (S{10mins}): {hh}:{m0}:{00}
- minute (S{min}): {hh}:{mm}:{00}
- TimeKey (S{TK}): S{10min} mapping to [0..143] integers closed interval
- timestamp (S{timestamp}): in seconds, the number of seconds passed since 1900.01.00 0:00:00
- StepSumiOS (S{steps}): number of steps taken in 10 minutes
- StepSumA (S{cumulative steps}): the number of daily steps taken to a given time
- StepType (S{st}): {raw, normalized}
- 10minNS (S{10mNS}): 10-minute normalized step data
- Neptun identifier (S{NID}): the NEPTUN identifier of the student submitting the data
- Person key (S{PK}): the hashed NEPTUN identifier of the student submitting the data
- Submission date (S{sd}): date of data submission in {year}{month}{day} structure
- ETL date (S{etld}): the date key of the ETL process in {year}{month}{day} structure
- From ‘source systems’ the data is loaded into an intermediate storage.
- We supplement each standalone file with the data in its name and the step type dependent on the mobile operating system.


The data from the Android phone (S{cumulative steps}) is a cumulative step number for a given time, so we must first calculate its dynamics (increment for the previous measurement).

Finally, we generate a common large data source from many individual files:

We generate 10-minute time intervals data from the activity tracker data. Data from the android phone Time property with minute accuracy is 10 minutes raw data, must be normalized as 10-minute accuracy data. The timekey value  will be a real number on the closed interval [0..144], the corresponding time key
will be a real number on the closed interval [0..144], the corresponding time key  is the whole part of the real number.
is the whole part of the real number.
Each S{steps} value must be broken down into the current 10-minute increments and the previous 10-minute increments. This brings out normalized Android bracelet data.

Data from the iPhone is 10-minute accuracy normalized data (S{10minNS}). The time key can be derived with the S{tkv} = Nr(S{10mins})*144 calculation.
We used a hash function (CRC32) on the Neptun identifier (hash(S{NID}) = S{PK}) before the step data is placed on the intermediate storage server created for our research as an excel table (10minsSteps.xlsx)
The result is the 10-minute normalized step data. 
4.4.2 Necessary/Existing Dimensionality Survey
D: dimDate (intermediate storage) unfolded hierarchical date dimension
- id (D{id}): unique identifier, continuous serial number {1..∞}
- DateKey (D{DK}): unique identifier; serial numbers of year, month, day with leading zeros, in {yyyy}{mm}{dd} composition
- Date (D{date}): (the number of days passed since 1900.01.00) in Microsoft date format
- Local Date String (D{lds}): year, month, day with leading zeros, in Hungarian date format, in {yyyy}.{mm}.{dd} composition
- Year D{year}: year identifier {yyyy}
- MonthNr D{monthNr}: month serial number {m}
- DayNr D{dayNr}: day serial number within month {d}
- MonthStrEn D{monthStrEn}: month name in English
- MonthStrHu D{monthStrHu}: month name in Hungarian
- MonthStrEnS D{monthStrEnS}: month abbreviation in English
- MonthStrHuS D{monthStrHuS}: month abbreviation in Hungarian
- Day of Week D{DoW}: serial number of weekdays{Monday, Tuesday, …, Sunday}->{1..7}
- WeekdayEn D{weekdayEn}: days in English
- WeekdayHu D{weekdayHu}: days in Hungarian
- DayTypeEn D{daytypeEn}: {weekday, weekend}
- DayTypeHu D{daytypeHu}: {hétköznap, hétvége}
- Day of Year D{DoY}: serial number of day of year {1..366}
- QuarterNr D{quarterNr}: serial number of quarters
- QuarterStrEn D{quarterStrEn}: quarter in English in Q{quarterNr} composition
- QuarterStrHu D{quarterStrHu}: quarter in Hungarian in {quarterNr}. negyedév composition
- WeekNr D{weekNr}: serial number of weeks {1..52}
- WeekStrEn D{weekStrEn}: week in English in W{weekNr} composition
- WeekStrHu D{weekStrHu}: week in Hungarian in {weekNr}. hét composition
T: dimTime (intermediate storage) unfolded hierarchical time dimension
- TimeKey (T{TK}): {0..143}, the ith 10-minute intervals of the day
- 10mins (T{10mins}): 10-minute duration in {h}:{mm}-{h}:{mm} composition
- 30mins (T{30mins}): 30-minute duration in {h}:{mm}-{h}:{mm} composition
- hours (T{hours}): hourly duration in {h}:{mm}-{h}:{mm} composition
P: dimPerson (intermediate storage) Person dimension
- PersonKey (P{PK}): students’ hashed Neptun identifier
- GenderEn (P{GenderEn}): students’ gender in English {Male, Female}
- GenderHu (P{GenderHu}): students’ gender in Hungarian {Férfi, Nő}
I: dimIntensity (intermediate storage) motion intensity dimension
- StepSumCategoryEn (P{sscEn}): motion intensity in English
- {Basal activity, Limited activity, Low activity, Somewhat active, Active, Highly active}
- StepSumCategoryHu (P{sscHu}): motion intensity in Hungarian
- {Alapvető aktivitás, Mérsékelt aktivitás, Alacsony aktivitás, Közepes aktivitás, Magas aktivitás, Nagyon magas aktivitás}
- DailyStepSumRange (P{dssr}): the ranges of the daily step category
- 0 <= DailyStepSum < 2500
- 2500 <= DailyStepSum < 5000
- 5000 <= DailyStepSum < 7500
- 7500 <= DailyStepSum < 10000
- 10000 <= DailyStepSum < 12500
- 12500 <= DailyStepSum
- 10minStepSumRange (P{10mssr}): the ranges of the 10-minute step category
- 0 <=10minStepSum < 250
- 250 <= 10minStepSum < 500
- 500 <= 10minStepSum < 750
- 750 <= 10minStepSum < 1000
- 1000 <= 10minStepSum < 1250
- 1250 <= 10minStepSum
4.5 Integration
During integration phase, we describe the production of fact tables and dimensions specified in the ideal data model to be used to answer the questions.
We determine indicators and dimensions needed for integration (not necessarily in this order), but as a result of integration, these should be a kind of documentation.
Finally, we determine the steps of the data loading process (ETL/ELT), looking at their sequence. Our strategies to achieve our integration goal are top-down (ideal model -> source) and bottom-up (source -> ideal model) strategies, both are widely used in information processing and knowledge ordering, in practice, they can be seen as a style of thinking, teaching, or leadership.
4.5.1 Indicators to be calculated to produce the fact tables:
10minNormalizedStepSum: 
DailySteps: 
Number of students: 
Number of active days: 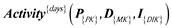
Average daily steps by gender and total: 
4.5.2 Additional dimension keys to produce
Daily intensity key: (I{DIK})
The basis for the categorization is the total number of daily steps of the person under investigation DS{step}(P{PK},D{DK}) ≥ {0, 2500, 5000, 7500, 10000, 12500} ⇒ {0, 1, 2, 3, 4, 5}, the necessary and sufficient dimensionality of the indicator is (P{PK},D{DK}) (; ). The result of the logical test is to categorize the number of daily steps of the examined person.
4.5.3 Necessary integration dimensions
T: Time (dimTime)
- TimeKey (T{TK}): {0..143}, the ith 10-minute intervals of the day
4.5.4 The data load ETL process
During this process, we load the S (Steps) relation properties of the source system and match the dimension keys of the fact table that contains the 10-minute normalized steps in the OLAP system in Table 8.
Table 8
10-minute normalized steps’ property mapping.
| OLTP system (extract) | transform | OLAP system (load) |
|---|---|---|
| S{10mNS} | => | 10minNS{step} |
| S{DK} | => | D{DK} |
| S{TK} | => | T{TK} |
| S{PK} | => | P{TK} |
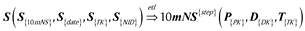
After the base ETL we load the dimensions (Tables 9, 10, 11) defined in the ideal data model and make the necessary conversions.
Table 9
Person dimension’s property mapping.
| OLTP system (extract) | transform | OLAP system (load) |
|---|---|---|
| P{PK} | => | P{PK} |
| P{GenderEn} | => | P{gender} |

Table 10
Date dimension’s property mapping.
| OLTP system (extract) | transform | OLAP system (load) |
|---|---|---|
| D{DK} | => | D{DK} |
| left(D{DK}, 6) | D{MK} | |
| D{DOW} | D{DoW}&“–”&D{weekdayEn} | D{weekday} |
| D{weekdayEn} | ||
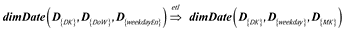
Table 11
Month dimension-hierarchy’s property mapping.
| OLTP system (extract) | transform | OLAP system (load) |
|---|---|---|
| D{DK} | left(D{DK}, 6) | DM{MK} |
| D{monthStrEn} | => | DM{month} |

After we have made the basic etl of the DateMonth dimension, the number of rows is related to DateKey granularity with monthly duplicated values, so we must deduplicate the rows noted as below in Table 12.

Table 12
Walk intensity dimension’s property mapping.
| OLTP system (extract) | transform | OLAP system (load) |
|---|---|---|
| I{IK} | => | I{IK} |
| I{IK} | I{IK}&“–”& D{sscEn} | I{dsc} |
| D{sscEn} | ||

We create fact tables defined in the ideal data model with data manipulation in our data warehouse.
4.5.5 ftDailyActivity: Daily activity fact table Activity{day}(P{PK}, (D{MK}, (I{DIK})
Daily steps: (DS{steps}): 10-minute normalized steps must be summarized up through Time dimension to get daily steps and extend the indicator with the daily intensity key.

Number of active days: Activity{day}: We must count the daily step related days in the month.

4.5.6 ftDailySteps: Daily steps fact table 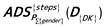
Average daily steps by gender and total: 
First, we summarize up the 10-minute normalized through Time dimension to get daily steps:
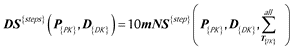
4.5.7 Method A (work with one indicator at a time)
Daily steps must be summarized up through Person dimension from PersonKey to gender level.
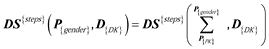
Pivoting the daily step indicator with gender attribute.
Calculate the gender independent daily step indicator summary.

Combine the three daily step indicators through the common DateKey into one fact table.
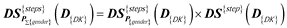
Students must be counted up through Person dimension from PersonKey to gender level.

Pivoting the student number indicator with gender attribute.
Calculate the gender independent student number indicator summary.

Combine the three student number indicators through the common DateKey into one fact table.

Combine the three daily step indicator fact tables and the three student number indicator fact tables through the common DateKey into one fact table.

The last step is to divide the three daily step indicators with the related three student number indicators to get the three average daily step indicators.

4.5.8 Method B (work with many indicators at a time)
First, we aggregate the daily step indicator with sum and count aggregate functions through the Person dimension from PersonKey to gender to get the daily step and student number indicators.
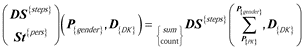
Next, we unpivot the daily step and student number indicators into value (V) and a special attribute (A) with values of the name of the unpivoted indicators.
Next, we combine the gender P{gender} and our special attribute A{DS,St} values into a new PxA{gender}×{DS,St} attribute.

Pivoting or new PxA{gender}×{DS,St} attribute values into our special (V) indicator to get four gender dependent daily step and student number indicators.
Calculate gender independent daily step and student number indicators by the summary of the gender dependent daily step and student number indicators and combine these two gender independent indicators, with the four gender dependent indicators.

The last step is to divide the three daily step indicators with the related three student number indicators to get the three average daily step indicators.
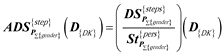
4.6 The Multidimensional modeling phase
We build the cube(s) with dimensions, dimension hierarchies and measures. In our example we implemented our galaxy schema (Figure 2) in Microsoft PowerBI, as the result of our hybrid methodology. We can see it in Figure 1. This data cube is the optimal cube to answer the researchers’ questions.
Galaxy schema of the optimal cube.
Researchers’ questions were:
- The students’ daily activity by daily steps intensity categories in March (and the preferred visualizing was table).
- Students’ average daily activity in March by category and gender (and the preferred visualizing was table).
- Mens’, womens’ and all average daily steps by the day of the week in March (and the preferred visualizing was radar chart).
On Figure 3, 4, 5 we can see the print-screens of the dashboards according to the questions. The data cube with dashboards () were implemented in Microsoft PowerBI also.
Table visualization of question1.
Table visualization of question2.
Radar chart visualization of question3.
5 Summary
In our study we presented a method and concrete designing tool that can decrease a serious deficiency in data warehouse conceptual design phase, when the customer and the vendor should think together to draw up the conceptual plan of a management information system. We provide a kind of ‘business intelligence problem solving thinking’ and a kind of descriptive language that can serve it. We proved with an example, that this approach could work very efficiently in a research area very popular nowadays, that is activity tracking. The problem we presented was simple and there were minimal quantity of management questions, but this hybrid conceptual modeling works in the same way during the conceptual design of a more complex management information system, the visual version of the design process of our example () results a very complex graph. The thinking method and the formalisation helps to describe the managerial questions exactly in the conceptual design phase, so it could be an effective intermediate language between designers and creators of the management information system in order to implement successfully, and in the long run help to supply the management or researchers with usual and correct information about their company or research.
Our method has a limitation related to the ETL process, because we focused on the transformation made after the extract-load processes first in the intermediate storage, and last in our Research Data Warehouse. In this example we are not defined notations for complex transformation of ETL process.