



1 Introduction
Modern industrial systems (no matter, global, regional, national, transnational etc.) are complicated, distributed, strongly interconnected networks of local facilities, producing, transporting and utilizing various products and resources. That’s why, – first of all, of the mentioned strong interconnectivity and associated with it multiple chain effects, – these systems are often vulnerable to natural disasters in such a way, that the one only facility destruction may cause consequences far beyond area or place this facility is located. So one of the most actual, important and at the same time difficult problems of the modern system analysis is development of the widely available mathematical toolkits, models and computer technologies, which would be able to provide the decision makers from the government and corporate stuffs with comprehensive and precise prognostic information about such consequences – first of all, would be system, affected by natural disaster impact (NDI), vulnerable or sustainable to it.
Industrial system (IS) in general case contains technological base (various industrial complexes and devices) producing (manufacturing) various objects (cars, computers, buildings etc.) and utilizing various resources (materials, microchips etc.), necessary for this process (Fig. 1a). Natural disaster destroys some segments of the technological and resource bases, that’s why amounts of objects produced are decreasing (Fig. 1b).
Industrial system: (a) in normal state; (b) after impact.
By this we may formulate criterion for IS robustness/vulnerability assessment (Fig. 2).
Possible consequences of natural disaster impact on industrial system.
If amounts of objects, produced by IS before and after natural disaster impact, are equal, then IS is sustainable to the NDI; otherwise it is vulnerable to the impact. In the last case there is also one more important “reverse” problem: what part of the work may be executed by vulnerable IS, which facilities are affected by NDI?
Let us consider formulated problems in more details.
As was said higher, IS include industrial (manufacturing) devices (complexes). Each such device may be represented as a “black box” B with m inputs and one output (Fig. 3). Every i-th input is marked by ai – name of object (item, resource) type, – and ni – amount (volume, quantity) of this object. So n1 objects (of type) a1, …, nm objects (of type) am are required for one object (of type) a manufacturing.
“Black box” representation of manufacturing device.
IS as a whole may be represented by k such “black boxes” B1, …, Bk interconnected by the “logistical ring” L, providing transport of objects, manufactured by devices, from their outputs to inputs of another devices, thus forming integrated manufacturing process (Fig. 4).
“Black box” representation of industrial system and order to be completed.
This process, however, is driven by orders, which sources are external systems or persons, consuming objects, produced by IS. Each order q in general case defines types and quantities of objects, which would be manufactured (n̄1 objects of type ā1, …, n̄l objects of type āl at Fig. 4). From the other side, IS itself consumes resources, which are represented at Fig. 4 as set I containing nl1 objects (of type) al1, …, nlp objects (of type) alp. By this, IS along with order also may be considered as “black box”, i.e. device producing object q after being applied to initial resources set I. Any impact on IS eliminates some initial resources and devices entering this system, thus reducing its producing capability.
Let us underline, that there are no static interconnections between devices B1, …, Bk, and structure, representing IS in the described manner, is not graph, usually considered as a canonical form of such systems description and modelling (; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ). Here every order completion provides its own tree, including manufacturing operations and transfers of their results among devices, incorporated to this process. Moreover, there may be a lot of variants of each order completion, by reason IS may contain devices manufacturing similar objects in different alternative ways. So, every order completion process generates, in fact, each own cooperation, or contracts set, providing necessary items manufacturing.
Described formalization is basic for direct and reverse problems, verbally formulated higher, primary consideration. But it is not sufficient for strict mathematical description and, further, necessary algorithms design. There would be some constructive mathematical toolkit providing solutions of mentioned problems. But multiple attempts of well-known general-purpose tools, based on vector-matrix calculus, graphs theory, Markovian chains, Petri nets etc. (; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ; ), application in the described area were not successful by reasons of problem’s dimension, difficulties of IS manufacturing process precise representation and computational complexity. This lead us to the new approach, which is, by our opinion, more flexible and simple in application to the large-scale IS representation, analysis and synthesis, as well as more efficient from the computational complexity point of view, especially in high-parallel computing environments. This new approach is strongly based on the recursive multisets (MS) theory (, ) – more precisely, multiset grammars (MG), – that’s why is called “multigrammatical”. Multiset grammars, namely, one of their possible dialects, – constraint multiset grammars (CMG) – were at first proposed in (; ; ) as a tool for recognition of visual objects with complex structure. CMG may be also considered as one of the problem-oriented constraints logical programming languages (; ; ).
Authors’ main contribution to this area are so called unitary multiset metagrammars (UMMG) (, ; ), which are specific knowledge representation model, providing deep integration and convergence of classical optimization theory and modern knowledge engineering. As shown in (, ; ), various subsets (subclasses) of UMMG provide efficient solution of various problems from system analysis and classical optimization areas.
Problem considered in this paper was announced in (), and it is solved mainly by applying one of the simplest classes of UMMG family – unitary multiset grammars (UMG). Also general form multigrammars are applied to the mentioned reverse problem study.
We consider main results of UMG/MG application to the problem verbally formulated higher in a following way. Section 2 is dedicated to basic notions and definitions. Main elements of the approach (technological base, resource base, impact on industrial system) multiset/multigrammatical representation as well as IS sustainability (vulnerability) conditions are described in the Section 3, while Section 4 is dedicated to the NDI representation and mentioned conditions transformation to the corresponding form. Reverse problem concerning recognition of the abilities of the vulnerable IS is considered in Section 5. Inplementation issues are discussed in short in Section 6. Further directions of the development of multigrammatical approach practical applications are described at the conclusion.
2 Basic Notions and Definitions
According to (; ; ; ; ), multiset is set of so called multiobjects of the form n • a, that means there are n identical objects (of type) a, and that is written as

where ν is multiset name, n1 • a1, …, nm • am are multiobjects entering ν, and integer numbers n1, …, nm are called multiplicities of a1, …, am objects, all of which are different. (1) means that there are n1 objects (of type) a1, …, nm objects (of type) am in multiset ν.
Unitary multiset grammar (UMG) is couple S = < a0, R >, where a0 is title object, and R is scheme – set of the so called unitary rules (UR) of the form

where a object is called head and list n1 • a1, …, nm • am – body of the UR.
UMG were designed specially for the representation of hierarchical systems and objects, so the most valuable in the considered problem area is so called structural interpretation of the unitary rules. According to the structural interpretation, UR (2) means that object a consists of n1 objects a1, …, nm objects am.
Example 1. Let S = < car, R >, where R contains two URs:
car → 1 • frame, 1 • engine, 4 • door, 4 • wheel.
engine → 1 • motor, 1 • accumulator, 1 • transmission.
As seen, car consists from one frame, one engine, four doors and four wheels. Engine, in turn, contains motor, accumulator as well as transmission.▪
Technological interpretation of unitary rules is extension of the structural one in such a way that UR

represents not only structural components (spare parts) of the object a, which are multiobjects n1 • a1, …, nm • am, but also resources, necessary for assemblying object a from these components, and being multiobjects n′1 • b1, …, n′k • bk.
Example 2. Let S = < car, R >, where R contains one UR:
car → 1 • frame, 1 • engine, 4 • door, 4 • wheel,
400 • kW, 300 • USD, 10 • mnt – asm – line.
Here first four multiobjects of the UR body are the same, as in the first UR in the example 1, while the last three multiobjects define amounts of electrical energy (400 kilowatt), money (300 dollars) and time (10 minutes of the assemblying line operation), which are necessary for assemblying car from its spare parts (frame, engine, 4 doors, 4 wheels).▪
Unitary multiset grammars define systems (devices, processes etc.) in the easily understood top-down manner, and result of UMG application is set of multisets, each containing multiobjects with multiplicities defining total amounts of specific elementary (non-decomposed) objects having place in the system (device) or utilized while its manufacturing. Degree of decomposition is regulated by the analyst applying this tool while problem solving.
To define formally UMG semantics, i.e. process of generation of set of multisets VS represented by UMG S, we shall use some operations and relations on multisets (, ; ). Lower +, – and * are symbols of multisets addition, subtraction and multiplication operations correspondingly, which are defined as follows:



Here symbols +, – and × denote usual arithmetic operations. In (4) we assume, that object a absence in multiset ν is equivalent to it’s zero-value multiplicity.
Lower we shall designate by β(ν) set of all objects having place in multiset ν (it is called multiset basis):

Symbol "⊆" denotes multisets inclusion relation, and, if ν′ ⊆ ν, then ν′ is called submultiset of ν. Formally

if

Also we shall use multisets intersection operation denoted by bold symbol “∩” and defined as follows:

As in (4), a ∉ ν and 0 • a ∈ ν are equivalent.
By As we shall designate set of all objects having place in UMG S = < a0, R >, while by A̅s – set of all terminal objects having place in S, i.e. objects which are not heads of unitary rules r ∈ R and present only in URs bodies. As seen,

Multiset ν ∈ Vs is called terminal multiset (TMS), if there is no one UR in the scheme R, which may be applied to ν, i.e. it contains only terminal objects. Set of terminal multisets (STMS) V̅s ⊆ Vs is subset of V:

Strict mathematical definition of the UMG application, i.e. set of multisets generation process, which we shall use here, is as follows (, ; ):



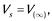

where UR a →n1 • a1, …, nm • am for unambiguity is represented in angle brackets, i.e. as < a →n1 • a1, …, nm • am >.
As seen, multisets generation is implemented by application to set of MS V(i), created at previous i steps, all unitary rules r ∈ R. In turn, every such UR is applied to all multisets ν ∈ V(i) by special function π of two arguments, first being ν, and second – UR r in the form a →n1 • a1, …, nm • am. If ν contains multiobject n • a, it is replaced by multiset n*{n1 • a1, …, nm • am} (this, of course, is followed by summarizing multiplicities of identical objects in the MS sum). Otherwise result is empty multiset. The described iterative process in general case is infinite, and set of multisets, defined by UMG S = < a0, R >, is it’s fixed point V(∞), while set of terminal multisets, defined by S, is subset of VS, defined by (17).
Let us note, that from computational complexity point of view (14) may be transformed to

where ∃∈ means selection of any one multiobject n • a from multiset ν. That provides sharp reduction of generation computational complexity (, ).
Here we shall consider only so called finitary UMG, which generate finite STMS (, ).
UMG S = < a0, R > is finitary, when there exists i such, that V(i+1) = V(i), and if so, V(i) = VS. Problem of UMG finitarity recognition is algorithmically decidable (, ).
Let us continue multigrammatical formalization of basic notions concerning the main subject of the paper.
Industrial system may be represented now by UMG S = < tb, R >, where tb (acronym from “technological base”) is title object, and R is set of unitary rules in technological interpretation. Order completed by industrial system may be represented by multiset 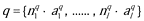 , and, evidently, resources amount, necessary for order q completion, is set of terminal multisets generated by UMG
, and, evidently, resources amount, necessary for order q completion, is set of terminal multisets generated by UMG
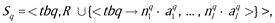
i.e. V̅Sq (for simplicity we shall use V̅q instead of V̅Sq lower). Because of possibility of multiple ways of some objects manufacturing, i.e. so called internal alternativity of Sq (, ), there may be more than one TMS in V̅q.
Example 3. Let S be the same, as in the previous example, and q = {3 • car }, i.e. IS must manufacture 3 cars. Then
Sq = < tbq, {< tbq → 3 • car >, < car →1 • frame, 1 • engine, 4 • wheel, 4 • chair,
400 • kW, 300 • USD, 10 • mnt –asm –line >} >,
(here UR are written in the angle brackets for unambiguity) and, as seen,
V̅sq = {{3 • frame, 3 • engine, 12 • wheel, 12 • chair, 1200 • kW, 900 • USD, 30 • mnt – asm – line }}. ▪
Resource base of industrial system may be represented by multiset, which multiobjects define amounts of objects, being available for technological base. Evidently, resource base ν is sufficient for order q completion by IS S = < tb, R >, if there exists at least one set of resources amounts, necessary for this completion, being submultiset of ν:

Example 4. Resource base
ν = {4 • frame, 3 • engine, 15 • wheel, 12 • chair, 1500 • kW, 1200 • USD, 50 • mnt – asm – line}
is sufficient for order q from the example 3 completion, while resource base
ν = {1 • frame, 3 • engine, 15 • wheel, 12 • chair, 1500 • kW, 1200 • USD, 50 • mnt – asm – line}
is not sufficient, because number of frames having place in the resource base, i.e. one, is less than it is necessary for 3 cars assemblying, i.e. three, although all other resources amounts are sufficient (they even exceed necessary values).▪
Impact on industrial system may be represented as multiset Δν, which defines resources amount eliminated from the resource base of IS, so the last after impact would be ν–Δν.
All introduced notions and definitions provide formulation of the condition of IS sustainability/vulnerability to impact.
Let resource base ν is sufficient for order q completion by IS S = < tb, R >, i.e. it satisfies (20). Then IS S completing order q with resource base ν is sustainable to impact Δν, if

Otherwise IS S is vulnerable to impact Δν.
Example 5. IS S = < tb, R > from example 3, completing order q = {3 • car} with resource base from example 4, sufficient for this order completion, is sustainable to impact
Δν = {3 • wheel, 2 • chair, 300 • kW, 100 • USD, 5 • mnt – asm – line}
because resource base after impact
ν–Δν = {4 • frame, 3 • engine, 12 • wheel, 10 • chair, 1200 • kW, 1100 • USD, 45 • mnt – asm – line}
is sufficient for completion. At the same time this IS is vulnerable to impact
Δν = {1 • engine },
because resource base after impact
ν = {4 • frame, 2 • engine, 15 • wheel, 12 • chair, 1500 • kW, 1200 • USD, 50 • mnt – asm – line}
is not sufficient for completion (number of engines is less than necessary).▪
3 Natural Disasters Impacts on Industrial System
Until now we have considered impacts without their specific features. Natural disaster impacts most general feature is their localization, i.e. connection with some fixed areas (points) affected by the NDI. However, any information about technological base, as well as resource base, elements locations, in the considered higher UMG representation of industrial systems is not included.
Let us extend unitary rules in technological interpretation by geospatial information in such a way, that every object, having place in UR, would have form a/z, where z is locator defining area (point), where this object presents, and “/” is divider, which is not used anywhere in a and z strings. So UR would have the following form:
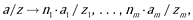
that means object a at location z may be produced (assembled) if there are n1 objects a1 at location z1, …, nm objects am at location zm. (Objects like a/z, a1/z1, …, an/zn are called “composite objects”, or “composits”).
Similarly, we shall extend resource base and order representation, which would become respectively


After that there is a simplest way for NDI representation, namely, by the set Z = {z1, …, zk}, of locations destroyed by this NDI completely. Corresponding relation for NDI in the multiset form is constructed directly:

and

From (23)–(24) and Z definition we may write the condition of IS sustainability/vulnerability, which is evident generalization of (21). If

then IS S = < tb, R >, completing order with resource base ν, is sustainable to NDI Z. Otherwise IS is vulnerable to Z.
Example 6. Let us consider IS, which resource base is
ν = {10 • a1/z1, 5 • a2/z2, 19 • a3/z3, 7 • a4/z4},
technological base is represented by scheme R containing two unitary rules
a/z1 → 3 • a1/z1, 2 • a2/z2, 7 • a3/z3,
a/z1 → 2 • a2/z2, 3 • a4/z4,
and order q completed by this IS is q = {2 • a1/z1}.
Natural disaster impact Z = {z3} causes destruction of subset of the resource base, located at z3, so according to (25),
Δν(Z) = {19 • a3/z3},
and
ν–Δν(Z) = {10 • a1/z1, 5 • a2/z2, 7 • a4/z4}.
As seen,
V̅q = {ν1, ν2},
where
ν1 = {6 • a1/z1, 4 • a2/z2, 14 • a3/z3},
ν2 = {4• a2/z2, 6 • a4/z4},
and
ν1 ⊈ ν – Δν(Z),
ν2 ⊈ ν – Δν(Z),
that’s why IS is sustainable to NDI Z.▪
Note, that NDI may destruct facilities not always completely, but very often partially. In this case some objects located at the area, affected by the NDI, may remain in the undestructed state and thus may be used elements for manufacturing some products.
This case may be represented in the direct manner:

that provides use of condition (27) for the IS sustainability/vulnerability assessment.
Example 7. Let us consider IS from the previous example 7, and NDI, partially destructing locations z3 and z4, so that
Δν(Z) = {12 • a3/z3, 2 • a4/z4 },
and
ν–Δν(Z) = {10 • a1/z1, 5 • a2/z2, 7 • a3/z3, 5 • a4/z4}.
As seen, because of
ν1 ⊈ ν – Δν(Z)
ν2 ⊈ ν – Δν(Z)
IS is vulnerable to NDI Δν(Z).▪
4 Reverse Problem
Let us consider the case, when IS R, completing order q with resource base ν, is vulnerable to NDI (Z or Δν(Z)).
The question is as follows: what part of order q may be completed by IS R affected by NDI Z?
Simple, but, however, non-evident approach to this question consideration is based on the general form multiset grammars use for constructing the solution.
Multiset grammar is couple S = < ν0, R >, where ν0 is multiset called kernel, and R is, as in the UMG, scheme, which elements are called rules, which structure is

where ν and ν′ are multisets. Semantics of multigrammars is similar to UMG semantics (, ):



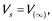

As seen, MG provides generation of new multisets from already generated, beginning from the kernel, by replacement of their submultisets in accordance with rules having place in the scheme. Generation is executed until it is possible, so, in general case, VS and V̅S may be infinite. However, if there exists i such, that V(i) = V(i+1), then V(i) = VS, then both VS and V̅S are finite sets, and MG is finitary.
Let us consider UMG S = < tb, R >, representing IS with technological base R, and this IS resource base ν. Multiset grammar  will be called dual to unitary multiset grammar S = < tb, R >, if
will be called dual to unitary multiset grammar S = < tb, R >, if

i.e. every unitary rule a →n1 • a1, …, nm • am having place in the UMG S scheme R is substituted by one and the only one “mirror” rule in MG 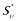 scheme R*.
scheme R*.
As may be seen, set of multisets  , generated by MG , contains all variants of production, which may be manufactured by IS S, beginning from the resource base ν. Set of variants of order q partial completion is, thus, subset of set generated by MG , each TMS of which contains at least one object from q order (here and lower we denote mentioned set of variants as V (R, ν, q)):
, generated by MG , contains all variants of production, which may be manufactured by IS S, beginning from the resource base ν. Set of variants of order q partial completion is, thus, subset of set generated by MG , each TMS of which contains at least one object from q order (here and lower we denote mentioned set of variants as V (R, ν, q)):

As a consequence, total set of solutions of the reverse problem is

Example 8. Let us consider IS with the same scheme R and resource base ν as in the previous examples 7 and 8, completing order q = { 3 • a/z1}, and being affected by the same NDI Δν(Z) as in the example 8. Kernel ν0 of MG S* = < ν0, R*>, dual to UMG S = < tb, R >, is
ν0 = ν– Δν(Z) = {10 • a1/z1, 5 • a2/z2, 7 • a3/z3, 5 • a4/z4},
while rules are
r1 ≡ {3 • a1/z1, 2 • a2/z2, 7 • a3/z3} → {1 • a/z1},
r2 ≡ {2 • a2/z2, 3 • a4/z4} → {1 • a/z1},
r2 ≡ {3 • a/z1} → {1 • tbq}.
According to (36),
V (R, ν– Δν(Z), q) = {ν1, ν2, ν3},
where
ν1 = {7 • a1/z1, 3 • a2/z2, 5 • a4/z4, 1 • a/z1},
ν2 = {5 • a1/z1, 3 • a2/z2, 2 • a4/z4, 2 • a/z1},
ν3 = {10 • a1/z1, 3 • a2/z2, 7 • a3/z3, 2 • a4/z4, 1 • a/z1}.
As seen, ν1 is result of application of r1 to ν0; ν2 – result of application of r2 to ν1; while ν3 is result of application of r2 to ν0.
So, a valuable part of the order (2 of 3 objects a located at z1) may be completed by the affected IS, and even some valuable part of the resource base would remain after following this way of order completion.▪
However, in general case some of multisets entering set V (R, ν – Δν(Z), q) may be of no practical use (as ν1 and ν3 in the previous example 8), because the only purpose of the assessment is to get the best (“valuable” in the common sense) variants of order completion, which are not improvable from the practical point of view.
To filter STMS, constructed in accordance with (37), we shall define one useful function max, which value max(V) is subset of V including only so called non-dominated multisets entering V:

i.e. there is no one multiset in max(V) ⊆ V, which is submultiset of some other multiset entering V; max(V) is thus set of maximal elements of V.
Example 9. Let V = {ν1, ν2, ν3, ν4}, where
ν1 = {3 • a1, 2 • a2, 1 • a3},
ν2 = {1 • a1, 2 • a2},
ν3 = {2 • a1, 1 • a3},
ν4 = {1 • a1, 3 • a2}.
As may be seen, according to (38), because of ν2 ⊆ ν1, ν3 ⊆ ν1, max(V) = {ν1, ν4}. ▪
From here set of valuable (“precise”) solutions of reverse problem, denoted V̅ (R, ν– Δν(Z), q) may be constructed in a following evident way:

As seen, set of valuable solutions includes those only intersections of elements of V (R, ν– Δν(Z), q) and q order, which are non-dominated multisets.
Example 10. Consider V (R, ν– Δν(Z), q) = {ν1, ν2, ν3} and q = { 3 • a/z1} from Example 9. According to (39),
V̅ (R, ν – Δν(Z), q) = max ({ν1 ∩ q, ν2 ∩ q, ν3 ∩ q}) =
= max ({{1 • a/z1}, {2 • a/z1}, {∅}}) = {{2 • a/z1}}.▪
Note, that general form multigrammars application instead of unitary MG provides generation of all possible variants of work distribution between alternative facilities (devices), not only monopolial ones. However, this opportunity as a consequence leads to sensitive increasing of computational complexity of generation mentioned. Theory and implementation of this complexity reduction would be considered in separate publications.
5 Implementation issues
Software implementation of IS sustainability assessment (“direct problem”) employs knowledge base (R set of unitary rules) representation and storage in a form of data base, which elements are selected by means of NoSQL-like (; ) query language.
Data base mentioned is set of records being couples of the form < a, B >, where a is object (key of the record) while B is set of bodies of unitary rules, which head is a:

where

so that (40)–(41) represent m unitary rules

While generation, set B is selected from data base by query, which processing is implemented by special function READ (a). Similarly, insertion of new unitary a→w to the knowledge base is implemented by function INSERT (a, w), as well as UR a→w deletion from KB (DB) is implemented by function DELETE (a, w). Also there is function DELALL (a), eliminating from KB all unitary rules with head a, i.e. deletion from data base record <a, B>, where B is current set of bodies of URs with head a.
Associative internal organization of the described data base along with physical blocks cash, supporting DB management via virtual memory space, provides fast execution of functions mentioned without redundant search ().
Software implementation of assessment of part of the order, which may be completed by the affected vulnerable IS (“reverse problem”) employs knowledge base (scheme R* of MG, dual to the initial UMG) representation and storage in a form of data base similar to the considered higher.
However, this data base contains records of two types:
- triples of the form <r, w, a>, where r is unique identifier (key of the record) of the “mirror” rule w→{1 • a}, where w multiset is represented as in (41);
- couples of the form <a, w>, where a is object (key of the record), while w is set of couples <r, n>, where r is identifier of rule, which left part contains multiobject n • a.
Example 11. Let dual UMG R* contains following “mirror” rules:
r1: {3 • a1, 2 • a2 } → {1 • a3},
r2: {2 • a1, 5 • a3} → {1 • a0}.
Then corresponding data base will contain following records:
< r1, {<a1, 3>, <a2, 2>}, a3>,
< r2, {<a1, 2>, <a3, 5>}, a0>,
< a1, {<r1, 3>, <r2, 2>} >,
< a2, {<r1, 2>} >,
< a3, {<r2, 5>} >.▪
As may be seen, quantity of records of the first type is |R*|=|R| while quantity of records of the second type is equal to number of objects having place in left parts of rules entering R*.
Records of the first type are used while generation of the TMS (i.e. solutions) set in accordance with (36)-(38) by application of “mirror” rules. If this would be done without any improvements, there would be full search of all |R*| rules at every generation step in order to apply some of them to the current multiset, generated while previous steps execution. So for practically interesting knowledge bases with |R*|, beginning from 105–106, direct implementation of generation algorithmics is unreal. To avoid this principal difficulty, records of the second type are introduced. They are stored and selected by key (object a) in such a way, that by one access to data base identifiers of all “mirror” rules, which possibly may be applied to current multiset by reason there is multiobject n • a in their left parts, and n ≤ m, where m • a enters current multiset. This techniques provides cut-off all the rest “mirror” rules, non-applicable to this MS by reason of object a absence in their left parts. There are several implementations of this basic idea, and they would be considered separately.
Described approach to software implementation of the proposed algorithmics is somewhat efficient from the practical point of view, that is verified by real software-intensive IS management experience (; ; ). Such software operates CALS-originated knowledge bases, which contain structural descriptions of all types of objects, manufactured by various facilities, entering distributed IS. Due to “granularity” of the described knowledge representation, all accumulation and correction of such KB from the distributed local sources is performed without any difficulties in the online regime. Assessment of the possibility of orders completion at moments, when they enter IS, is performed in soft real time mode (minutes per message) on knowledge bases containing 10–12 mln. unitary rules with 2–3 mln. type of objects (items) used and manufactured by the industrial system, and this mode does not require special-purpose or high-parallel hardware. Reverse problem software is activated, when various impacts like manufacturing equipment malfunctions and necessary resources delays occur, and is solved on the same hardware in practically the same time scale. More detailed description of the UMG toolkit software implementation in various hardware environments may be object of the special paper.
6 Conclusion
Multigrammatical approach shortly presented in the paper may be efficiently used for the assessment of consequences of natural disasters impacts (as well as human-implemented impacts) on large-scale industrial systems, no matter what production they are manufacturing, what infrastructure they use, what kind of producing devices they contain etc., due to the generality and flexibility of MG/UMG toolkit used for the assessment.
The main four directions of further development of the approach, in our opinion, are:
- application of so called temporal MG/UMG with parallel processes modelling features to more deep and adequate assessment of NDI consequences;
- implementation of “what-if” regimes for decision makers;
- minimization of computational complexity of multisets generation as well as high-parallel generation algorithms development for grid/cloud hardware;
- development of “Big Knowledge” paradigm and unconventional computational models for its hardware implementation.
The first direction background is following. As it is easy to see, multigrammatical approach is strongly based on the additivity of quantities of objects represented by their multiplicities. However, time is additive only in consideration to one processing (manufacturing) unit (for example, assemblying line): if there are two or more such units, they may operate in parallel, that’s why total work may be completed by the system faster than in the sequential mode with additive time operating. Temporal MG/UMG are such generalization of the considered higher mathematical tools, that provide simple description of industrial systems and their elements extended by time intervals which are necessary to these elements to execute operations. Basic construction of temporal unitary multiset grammar is so called temporal unitary rule of the form

where t is fixed object denoting time measurement unit (for example, minute) while n multiplicity is duration of time interval (number of t objects), necessary for assemblying a object by utilizing n1 units of resource a1, …, nm units of resource am. This extension provides as a final purpose construction of Gantt diagrams charts of manufacturing (production) processes evolving all devices which are necessary for order completion, that’s why temporal MG/UMG algorithmics is in fact algorithmics of optimal (rational) scheduling (; ). It is much more deep and sophisticated in comparison with MG/UMG, however, providing practically useful generalization of well known scheduling problems and their solutions.
The second of the listed directions is from the practical point of view very important, because it provides end users (decision makers) with the opportunity to prepare to possible NDI before they really occur.
The third direction, being quite evident, follows from the non-procedural, declarative representation of the knowledge about industrial systems and their operation items. “Granularity” of multigrammatical knowledge bases provides easy, in fact, “additive” accumulation of knowledge as well as its correction.
However, like any other knowledge representation model, MG/UMG need special algorithmics providing minimization of redundant search while multisets generation, especially for the so called filtering MG/UMG (, ; ; ). This direction is, perhaps, most critical, because it eliminates or mitigates sharp growth of redundant generation steps, which reason is well-known combinatorial explosion while knowledge base volume expansion. There would be combination of two basic approaches for such kind of problems solution: redundant steps elimination by some smart cutting-off conditions exploitation at maximal early stages of multisets generation, and “brutal force” application by parallel generation of alternative branches on asynchronously operating processor units. State of the art in this area is described in (, ).
The most general is, in our opinion, the fourth direction. As may be easily estimated, real large-scale industrial systems technological bases and IS production (manufactured objects) would be represented by UMG knowledge bases containing millions and millions unitary rules. Creating, maintaining and utilizing such amounts of knowledge is a great problem being the next step of computer technologies application after Big Data, which are in fact everyday reality, however, not yet understood () (as may be seen from section V, when UMG are used, then Big Knowledge is implemented by Big Data tools). In many considerations, it would be a new way of thinking, which must lead us to the new understanding of the global technosphere as an interconnected set of devices, joined with one another by information infrastructure (that’s already “Internet of Things”) and logistical networks. Such understanding, in turn, may optimize humanity behavior and its relations with the nature.