



1 Introduction
As many industries and research labs handle increasing amount of data in materials science, big data () is being considered as an important issue for materials engineering services. Extracting meaningful and valuable information from large-scale datasets is essential for providing new applications as well as improving the quality of existing services. Data management, reuse and collaboration in various sources pose new challenges to the field of materials science (; ).
In recent years, along with the continuous accumulation of scientific data and the constantly changing of practical requirements, the “big data” management issues should be addressed in the aspect of domain scientific data. Materials scientific data comes from lab experiments, simulations, individual archives, enterprise and internet in all scales and formats. This data flood has outpaced our capability to process, analyze, store and understand these datasets. Materials science data possess the typical characteristics of big data.
- Volume: Massive materials scientific data have been accumulated in the past several decades. This provides large amounts of available data, but makes it more difficult to rapidly obtain valuable information.
- Variety: Materials scientific data are distributed in different sources and heterogeneous data are manifested in different formats, such as sheets, semi-structured XML, non-structured images, etc.
- Velocity: Materials scientific data are constantly changing, especially the experimental data. Many of the data sources are very dynamic, and the number of data sources is also expanding.
- Veracity: Materials scientific data sources are of widely differing qualities, with significant differences in accuracy and timeliness. Highly precise data are required in most of the engineering services.
The problem we mainly focused is how to manage materials scientific data in an intelligent way for better services based on users’ requirements. The issues addressed for meeting the user demands in data services include: extract valuable data from variety resources and remove the redundant data; represent data information by mining the complex relationships in datasets; compose data queries using specific domain terminology; adapt changing requirements of the users in data organization. Thus it is difficult to meet these demands for data services using traditional technology. A new service model is required in this circumstance.
The main objective of this paper is to present the modelling and construction method for Virtual DataSpaces (VDS) for managing big data and providing data services in the field of materials engineering. The concept of VDS is proposed (), which is different from the traditional data management technology. VDS is not only developed from dataspace () but also represents an innovation in the deepening of it. As a new mode of data organization, VDS not only illustrates a new modelling method to organise and process the big data but also presents a new evolution method to manage the continually changing data, services, and user demands. VDS faces the complex data management and dynamic service demand in the field of materials engineering. The process and algorithm of VDS construction is based on the user feedback. Finally, the effectiveness of the model is verified by the case description of a materials science domain application and the comparisons of different models are also shown. VDS has its own characteristics, such as the modelling ideology of “data first”, the subject related, the domain knowledge model, the emphasis of “services”, the support of data-associated mapping and dynamic evolution, the real-time and on-demand service, etc. Therefore, the new mode “VDS” is suitable for effectively managing big data and dynamically providing intelligent services in materials engineering.
In addition to the introduction section, there are six sections in this paper. The rest of this paper is organised as follows. In Section 2, the previous work about big data management and intelligent services is introduced, and the related research about dataspace is investigated. In Section 3, the modelling theory and construction method of VDS is described. In Section 4, the evolution process of VDS is elaborated and analysed. In Section 5, the analysis and comparison between VDS and other models is discussed, and the application case of an intelligent service in the field of materials engineering is proposed. Finally, the conclusion and further work is presented in Section 6.
2 Related Work
2.1 Big Data
Both theoretical and practical studies on big data management have got increasingly attention given the background of new challenges. Several important characteristics about big data have been enumerated and the platform requirement challenges for big data architecture have been described (). An overview of the research issues and achievements in the field of big data analysis has been provided and the multidimensional data analysis problems about big data have been discussed (). A new algorithm with the help of a semantic graph for the more efficiently and intelligently processing big data has been proposed (). However, because the semantics of big data are only described with RDFs, it has limited semantic representation ability. Active data () as a programming model has been proposed to alleviate the complexity of the data lifecycle and automatically improve the expressiveness of data management applications. However, this model does not consider the semantic association characteristics and does not form a refined ideology about dynamic evolution.
The formalisation of a time window selection strategy along with a literature review is presented (). This study analysed the improvement in churn-model performance by extending the customer event history from one to sixteen years and uses logistic regression, classification trees and bagging in combination with classification trees. Using a time window could substantially decrease data-related burdens, such as data storage, preparation and analysis. This is particularly valuable when decreasing computational complexity is paramount. A new method to create necessary summary information by reducing the dimension of a coalition transaction data is proposed () to develop a behaviour-scoring model and contribute big data analysis for a coalition loyalty program. For addressing the problem of big data analysis in the new business intelligence era (), evaluated the causality between the data set characteristics as independent variables and the performance metrics as dependent variables using a multiple regression method. These methods and ideas about big data processing provide a guide for our work.
2.2 Intelligent Service
An intelligent service refers to a service that automatically recognises the explicit or implicit user demands and then meets those demands proactively, efficiently, safely and accurately. The prerequisites for an intelligent service software environment include a standard information infrastructure, a data accumulation that can be efficiently used, the opening and sharing about data services, and quality assurance about data legitimacy. Related research about intelligent service environments has developed to a certain extent in recent years. Intelligent service environments might become increasingly important with the development of big data in the future.
A novel Artificial Neural Network (ANN)-based service selection (ANNSS) algorithm () was proposed to overcome the shortcomings of blindness and randomness in traditional service selection algorithms. The novel algorithm chooses exactly the most appropriate service in a ubiquitous web services environment. An intelligent service-integrated platform () has also been proposed. It employs the software agent as the framework to construct an integrated information system mechanism for preventing monetary loss due to the information gap. It also employs radio frequency identification (RFID) technology to realise the smart shelf as the trigger point for the retrieval of commodity messages. This framework might help enhance the performance of sales outlets and improve customer service while addressing the time effect issue with a popular commodity.
A solution for the converged context management framework has been presented (). This framework takes advantage of the features of intelligence and convergence in next-generation networks. At the same time, it allows the seamless integration, monitoring, and control for heterogeneous sensors and devices under a single context-aware service layer. This layer is centred on a context intelligence module that combines clustering algorithms and semantics to learn from the users’ usage histories, and takes advantage of this information to infer missing or high-level context data. Finally, it provides personalised services to end users using a context-aware method. The mobile agent based on a distributed geographic information service system has been created using the intelligent service chain construction technology (). A web-based intelligent self-diagnosis medical system (Pyung-Jin, Heon & Ungmo 2009) has been presented to go beyond finding the name a disease by suggesting synthetic preventive health care methods based on analysing lifestyle, food and nutrition. These technical methods and service architectures for intelligent services have a reference value for our research.
2.3 Dataspace
Researchers are trying to seek a new technology to address the new challenges of big data management and the intelligent service environment. Since the proposal of the concept of “dataspace” () as a new mode of data service, researchers have designed wide variety of dataspace models and have proposed several prototype systems that are consistent with their respective needs.
From the perspective of data, the essence of a dataspace is a collection of big data. Dataspace technology could be used in a wide range of areas, such as Personal Information Management (PIM), organising and processing scientific or engineering data, social network, and so on. The model research is the basis of dataspace construction. With the different domain features, there might be different data models to describe and organise the complex data for different service requirements. The primary existing dataspace models are as follows:
- iDM (iMeMex Data Model)
The iDM is the dedicated data model of the iMeMex system (). It organises and expresses all of the personal data resources in the form of a resource view and a resource view class. The iDM is the first dataspace model that is able to describe heterogeneous personal data resources in a unified form. However, this model uses a new query language, iQL, which based on XPath and a SQL-like query language. For ordinary users, it is difficult to get started quickly. - UDM (Unified Data Model)
UDM is a data model that is suitable for desktop search systems (). UDM adopts the database/information retrieval (DB/IR) integration approach that is able to dive into data items to retrieve the desktop dataspace. However, its new query language TALZBRA is very complex, and this model does not support shortcut queries. - Probabilistic Semantic Data Model (P-DM)
P-DM is a dataspace model completely based on probability (). P-DM uses the probabilistic mediate schema () and probabilistic semantic mapping to achieve the semantic integration of heterogeneous data sources. This model addresses the problem of uncertainty (; ) in different levels of dataspace and supports the top-k query response that could improve the quality of queries. However, its schema matching probability is not very accurate, and the model is difficult to extend. - Domain Model
The Domain Model is a dataspace model that is similar to the ontology method (; ). It supports a simple semantic query operation, but the mapping between the domain model and the data sources needs to be constructed manually. - CoreSpace Model & TaskSpace Model
The CoreSpace Model and the TaskSpace Model are the core parts of the personal dataspace management system, OrientSpace (; ; ), which automatically constructs a personal dataspace. This system considers the behaviour characteristics of the subject, and highlights the effect of subject characteristics on the dataspace. However, an in-depth discussion about the inconsistency and the optimisation of the weight calculation is needed. - Triple Model
The Triple Model is a flexible data model () that is similar to the RDF and expresses heterogeneous data in the form of triples. This model represents the hierarchy of file resources through a graph model, thus it can express the heterogeneous data simply and flexibly in dataspace. However, the Triple Model does not support path expression queries, does not consider uncertainty, and queries by Subject Predicate Object (SPO) are difficult.
In addition to the above six models, there are some other dataspace models, such as the resource space model (RSM) (), the PAD model (), etc. They provide the related theoretical basis for dataspace research.
Researchers have developed several prototype systems based on the model research about dataspace. The prototype of iMeMex supports a keyword query, a structured query and a path query, but does not support a semantic query (). Semex () is a prototype system that supports a neighbouring keyword query based on the domain model and global relational view, but it lacks a full-text index about the text content and unduly depends on the model. OrientSpace (; ) is a personal dataspace prototype system that supports the “pay-as-you-go” method. It supports incremental optimisation of the data service by constantly changing based on user behaviour analysis. These prototype systems are all personal dataspaces, and are not very similar to the scientific dataspace in the field of engineering application.
PAYGO () supports automatic pattern matching and similarity clustering analyses that support automatic evolution based on user feedback, but it lacks a detailed description. UDI () supports the mode merge and automatic evolution, but its assumption is too simple and restricts the scope of application. Roomba () is the first dataspace system that genuinely emphasises evolution. It introduces a user feedback mechanism, stores the data using generic triples, and adopts the method of instance-based string similarity matching. Quarry () materialised data to generic triples and realised data integration using the global mode, but it occupies a large amount of storage space.
CopyCat () embodies a more interactive data integration approach based on the SCP (Smart Copy and Paste) model. This prototype supports system optimisation by automatically learning based on user feedback. Similar to CopyCat, Octopus () is a dataspace prototype system that includes a variety of functions, such as searching, information extraction, data cleaning, data integration, etc. It supports keyword search and provides the “best-effort” operation based on query relevance ranking. These two prototype systems both do not distinguish the different stages of the lifecycle, but rather try to seamlessly integrate all of the stages of dataspace.
The Self-Organising Maps (SOM) () method was used to screen the level of satisfaction of dialysis patients in the NephroCare network, which belongs to Fresenius Medical Care (FME), a global provider of dialysis services. SOM is a neural network model for clustering and projecting high-dimensional data into a low-dimensional space, and it could support the identification of potential improvements for specific patient groups by analysing data provided by a questionnaire. This method could preserve the topological relationships of original high-dimensional dataspace; therefore, its idea is a good inspiration for dataspace construction.
The above dataspace prototypes have more or less satisfied the specific demands of big data processing, such as semantic integration, pay-as-you-go, schema mapping, etc. However, most of them are limited by the coarse-grained architecture research and model construction, and rarely consider the issue of demand-oriented dynamic evolution in the modelling process of the dataspace. Meanwhile, these prototypes do not provide the data service features in the field of materials. Based on this previous work, we propose the concept and method of Virtual DataSpace (VDS) (). This technology could convert physical data into virtualisation processing, achieve the dynamic evolution of data and realise the individualised on-demand service based on data associate modelling. It is necessary to deeply research the modelling process and the evolutionary algorithm of VDS for big data processing and intelligent services in the field of materials engineering.
3 Virtual Dataspace Model
3.1 VDS Definition
VDS is a new scientific data service mode that faces the domain demands of an engineering expert system, especially the materials application demands. It can be defined as follows.
VDS denotes the sets of data, services and their relationships with the subject of user requirements by supporting virtualisation processing and dynamic evolution. VDS is composed of four-tuples, VDS = (SUR, DS, DRS, SS). SUR is the subject of user requirements, which mainly refers to the demands of user; DS is the data resource set; DRS is the data relationship set among the data resources; SS is the service resource set.
According to the definition of VDS, VDS means the collection of data resources and services that relate to the specific subject. It uses virtualisation technology and the dynamic () evolution method to expand the data resources and service resources in accordance with the actual needs of subjects. From the basic structure on the relationships of subjects, data sets, and services in VDS (Figure 1), it is noted that the “subject” is also the user who uses the “virtual data” for their specific needs.
The basic structure of the relationships between subject, data sets, and services in VDS.
Considering a specific data item, VDS also could be described as an m-dimensional vector. VDS = (V1, V2, … , Vm), where Vi is an n-dimensional vector, Vi = (Pi1, Pi2, …, Pin) and Pij is an instance of a triple (subject, data set, service). Thus, VDS is an m*n-dimensional space as in Eq. (1).

Describe the relationship of data, services and subjects in VDS as an m*n-dimensional matrix as in Eq. (2).
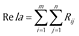
Rij is a Boolean value. Consider the data, services and subjects as the basic element items, represented as Ek. When a correlation exists between two element items, for example, Ei is related to Ej, thus Rij is assigned to 1; otherwise it is 0. The total number of relationships is m*n.
Around a particular subject such as “the automobile manufacturers need high hardness material for car board”, according to the associated construction of this subject, the subject-specific VDS is obtained as in Eq. (3).
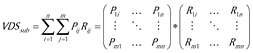
Assume that the number of Rij, which is equal to 1, is N, then obtain the subject-related VDS as an N-dimensional vector, VDSsub = (P1, P2, …, PN), thus, VDSsub is an m*n-dimensional space as in Eq. (4).

Because VDSsub is around the same subject, sub1 = sub2 = … = subN. Accordingly, one could obtain the data and services that are of interest to the particular users, i.e., obtain a particular VDS based on the requirement of the subject. Therefore, VDSsub also could be considered as a subset of VDS.
Based on the above theoretical analysis, the working process of VDS could be divided into three main stages (Figure 2). (1) In the initialisation phase, users have not accessed the data, thus there are no associated relationships between data and subjects. (2) In the use phase, gradually establish the associations between users and the data of interest along with the accessing and manipulating of data by the subjects. (3) In the evolution phase, join the users with their data of interest to form a dedicated space that also could be automatically optimised according to changes in the users’ interests and requirements.
The working principle of VDS in different stages.
3.2 VDS Model Construction
The construction of VDS model mainly includes three steps, build semantic data view, establish user requirement model and match schema automatically.
The construction of the global semantic data view () is the primary condition of realising the automatic mapping between the local data sources and the global model. The global semantic view could be defined as, GSV = (Cs, Rs, Is, As, Rus), where Cs represents the domain core concept sets. Rs denotes the semantic relationship sets of domain concepts, i.e., Rs = C1*C2*…*Cn. Is are the instance sets. As denotes the axiom sets about the domain concepts and relationships. Rus represents the Horn rule sets, which support the discovery of domain implicit knowledge by rule-based reasoning.
To further increase the expression strength of an associated relationship between core concepts, we also include a certain number of constraint axioms into the global semantic view. The constraint axioms can be classified as two types: the value constraint, which constrains the range of attribute, and the cardinality constraint, which constrains the quantity of value.
In addition, OWL DL () is also a good ontology description language that has a stronger semantic expression and reasoning function. Therefore, its constraint axioms also could be used to describe the global semantic view.
Considering the “subject” as the core concept of VDS, it is important for both the “data” and the “service”. Thus, subject mainly refers to the user requirement. It is necessary to analyse the relationship between subject and the other elements in VDS, we find complex relationships among subjects and users. The user maps to different subjects according to his/her demands, whereas a specific subject could be applied to different users. Data items and services are organized by subjects in VDS. This management is evolved according to different requirements and using behaviour.
User Requirement Model (Figure 3) is defined as a set of four-tuples, URM = (CI, RI, WI, TI), where CI denotes the core concept sets that the subject is interested in, CI = Ckey + Ctemp, where Ckey defines the keynote requirement and Ctemp denotes the temporary requirement. RI denotes the associated relationship of core concepts. WI denotes the weight value of concept, i.e., the interesting degree of the subject for a core concept. TI denotes the update time of WI.
The user requirement model of VDS.
The schema mappings are built automatically among data items, data sources and global semantic view. It is constructed by a semantic query, which reinforced the relationships between semantic concept items. Ontology similarity is used in this method to achieve automatic schema mapping. This measurement could be defined as,

where C1 and C2 are the semantic concept items. C1i denotes the sub-concept in C1 and C2j denotes the sub-concept in C2. If the attributes or the instances of concepts c1 and c2 are the same, the concepts c1 and c2 are the same. If the sub-concept (i.e., subclass) or parent concept (i.e., super class) of concepts c1 and c2 are similar, then the concepts c1 and c2 are similar. If all of the sub-concepts or brother concepts of c1 are similar with the concept c2, then the concepts c1 and c2 are similar.
Therefore this model only contains the data and services that are required by the subject. It adopts the manner of pay-as-you-go, thus the overhead of construction is quite small. This model is gradually improved along with the use of data by the subjects.
4 Model Evolution Based On Services
The changing demands in data services require the model evolution in VDS. The evolved model could help better adoption of VDS along with the service time and changing requirements. On one hand, the changes in services and user requirements from time to time lead to continuous changes in data items of VDS. On the other hand, the changes of semantic relationships and information in applications are changing due to the heterogeneous data sources.
The evolution of user requirements means the changes in interest areas of the subject that are embodied in the user feedback. The user feedback is mainly described as two parts. One is the feedback of the requirement model (i.e., the interest model), which supports the amendment of core concepts by subjects. Each subject could correct the interest model according to their own demands, and would not affect the use of VDS by other subjects. The other is the feedback of pattern matching results. It supports feedback correction for the results of pattern matching by subjects in the process of automatic matching and mapping between the local data source mode and the global mode.
In VDS, users feed their expectations and intentions to the system through the feedback instance. The user feedback instance could be described as follows.
The User Feedback Instance is a set of four-tuples, UFI = (AttV, RG, Exp, Prov), where AttV is a set of key-value pairs that is composed of the attributes and the corresponding values, i.e., AttV = <atti, vi>, i ∈ [1,n]. RG denotes a set of associated relationships in the global model. Exp is a Boolean value, which supports determining whether the attribute key-value pairs “AttV” could meet the user expectations. Prov denotes the provenance of feedback that could be specified by the user and could be automatically obtained from the candidate matching.
For example, Prov1 = <‘huserSpecified’, MD>, where ‘huserSpecified’ denotes that AttV is specified by the subject. MD denotes that the attribute key-value pairs “AttV” is automatically obtained from the data source in the process of pattern matching. MD is a set of candidate mappings, which supports retrieving the AttV from heterogeneous data sources, i.e., MD = <m1, m2, … , mk>.
Another example is UFI2 = ({<Type, ‘Nano Materials’>}, SPoSM, false, {m2}). This feedback instance means that the type of ‘Nano Materials’ could not meet the needs of “Service Performance of Structural Materials (SPoSM)” according to the candidate matching “m2”. Actually, this is a ‘nano-material’ rather than a ‘structural material’.
Table 1 illustrates the evolution algorithm of schema matching using the feedback instances. First, select a set of candidate mappings as input. Second, in the input mapping, automatically obtain the information about classes, attributes and relationships from the local mode and the global semantic view. Next, annotate the matching and mapping between the local data source mode and the global semantic view using the user feedback instances. Then, identify cases where matching or mapping does not meet the user requirement. Finally, construct the new mapping by correcting and merging the current mappings that meet the user requirement and return the refined mappings.
Table 1
The evolution algorithm of schema matching using the feedback instances.
| Algorithm. RefineMappings (Map Mi, UFI instan) | ||
| Inputs Map: A set of candidate mappings | ||
| UFI: A set of user feedback instances | ||
| Outputs Map: A set of refined mappings | ||
| Begin | ||
| 1 | If (Mi ≠ null){ | |
| 2 | S_Map = Mi; | |
| 3 | O_Map; | |
| 4 | Foreach OL ∈ S_Map { | |
| 5 | If (OL ≠ null) | |
| 6 | {Add <OL, OG> To O_Map} | |
| 7 | } | |
| 8 | AnnotateMappings(O_Map, UFI); | |
| 9 | C_Map = CombineMappings(O_Map); | |
| 10 | Return C_Map; | |
| 11 | } | |
| End | ||
Overall, dynamic evolution is an important feature of VDS, which is different from the traditional approach of data management. Based on the research of the dynamic evolution mechanism, users could quickly acquire more efficient data management and the individualised intelligent services.
5 Experimental Results
5.1 Comparison with other models
As a new data logical organisation and data management method, VDS has its own characteristics. Table 2 illustrates the characteristics comparison between VDS and traditional data management methods.
Table 2
Characteristics comparison between VDS and traditional data management methods.
| Traditional database | Semantic data integration | VDS | |
|---|---|---|---|
| Data object | Data in relational database | All data | All data |
| Data mode | Relational model (Schema-First) | Ontology model (Schema-First) | Multiple models (Schema-Later) |
| Data type | Structured data (tables) | Structured data, Semi-structured data, Non-structured data | Structured data, Semi-structured data, Non-structured data |
| Data source | Single source, isomorphism | Multi-source, heterogeneous | Multi-source, heterogeneous |
| Data association | Simple association, structural stability | Complex association, structure is relatively stable | Complex association, dynamic evolution |
| Semantic | Without semantic | Pre-established semantic information | Gradually improved semantic information |
| Quality of data access | Accurate and complete results | Accurate and complete results | Currently optimal results (Best-effort) |
| Construction and services | First building, after use (Pay-before-you-go) | First building, after use (Pay-before-you-go) | Construction and optimisation with use (Pay-as-you-go) |
Through comparison with the traditional modes, VDS has the following significant features: (1) complex association with multi-source and heterogeneous data; (2) virtualisation processing; (3) pay-as-you-go, incremental improvements to the data model; and (4) on-demand service mode, dynamic evolution with the changes of user requirements. In short, VDS is a data service mode with the feature of “data first”, “schema-later”, and “best-effort”.
Considering the big data management needs to quickly obtain the valuable information from the complex data, an intelligent service mainly involves getting the required knowledge with a high value density from the related data with a low value density. The technical characteristics of VDS could well satisfy the needs of big data processing and intelligent service. Therefore, VDS is a more optimised technical method, and is suitable for solving the various issues of intellectualised big data services.
Although the current research about dataspace models has been studied, most of the applications are concentrated in the field of Personal Information Management (PIM). There are some generic models, but most did not give the application examples in specific areas. For the VDS proposed in this paper, we developed a “Materials Scientific Data Sharing Service Platform” based on the construction of a Materials Virtual DataSpace (MatVDS) to implement intelligent service applications in the field of materials engineering. Those with a focus on the field of materials engineering are very scarce. Table 3 illustrates the comparison of dataspace models from various aspects such as the data source, the model internal principle, the integration method, the field of application, and so on. This comparison shows differences in the construction method and function of these models. Unlike the needs of personal data management, VDM is applied to the engineering field; therefore, it has a complex construction and implementation. VDM fully considers the user demands and emphasises the central position of the subject. Furthermore, VDM uses the ontology as the realisation technology of the model; thus, it has a unique advantage in resolving the problem of semantic heterogeneity.
Table 3
The model comparison of dataspaces.
| Model comparison | iDM (ETH Zürich) | UDM (University of Washington) | P-DM (Stanford University) | T-DM (Carleton University) | CSM (Renmin University of China) | VDM (USTB) |
|---|---|---|---|---|---|---|
| Data source | Centralised, heterogeneous data | Centralised, heterogeneous data | Distributed, heterogeneous data | Distributed, heterogeneous data | Centralised, heterogeneous data | Distributed, heterogeneous data |
| Model structure | Based on the graph | Based on the sort tree | Based on the probability mode | Based on the RDF | Based on the graph | Based on the ontology |
| Integration approach | Only database | Database, information extraction | Data integration | RDF | Association rules | Semantic integration |
| Applicable field | Personal Information Management (PIM) | Personal Information Management (PIM) | Not involved in the specific application areas | Not involved in the specific application areas | Personal Information Management (PIM) | The field of materials engineering |
| Uncertainty | Does not support | Does not support | Support | Does not support | Does not support | Support |
| Subject feature | Does not consider | Does not consider | Does not consider | Does not consider | Individual users as the core | Users in material field as the core |
| Applicability | Good query performance, and support the semantic | Query interface | Support the top-k sorting query results | The processing capability of query language is strong | Support the multi-faceted semantic queries | Diversified query strategy and strong semantic support |
MatVDS has realised the automatic construction of a virtual dataspace for the application of materials engineering. Table 4 and Table 5 illustrate the comprehensive comparison of MatVDS and other dataspace systems in the process of automatic construction. The comparison shows that MatVDS focuses on complex and distributed data sources in the field of materials. The integration approach of MatVDS is more flexible. MatVDS supports the combination of automatic and manual, i.e., pre-completed part of the integration work before use; and gradually improves it using the method of “pay-as-you-go” in the use process. MatVDS provides a diversified query strategy, and the query service system is a better fit for the actual needs of the engineering field. The automatic construction of a dataspace system is difficult and complex. The process of pursuing automation inevitably results in the loss of accuracy to some degree. These losses are acceptable in MatVDS and future research will focus on how to improve the accuracy of automatic construction.
Table 4
The comparison of MatVDS and other dataspace systems in the initialisation phase.
| Prototype system | Data type | Location of data source | Integration model | Type of schema integration | Processing of schema integration | Endpoints of schema matching | Processing procedure of mapping |
|---|---|---|---|---|---|---|---|
| MatVDS | Structured (stru), semi-structured (semi), unstructured (unst) | Local, distributed | Proprietary model | Union, merge | Automatic, manual | Source mode (sour) and integrated mode (inte) | Automatic |
| OrientSpace | stru, semi, unst | Local | Proprietary model | — | Automatic | — | Automatic |
| SEMEX | stru, semi, unst | Local, distributed | Proprietary model | Merge | Manual | sour & inte | Automatic |
| iMeMex | stru, semi, unst | Distributed | Proprietary model | Union | Automatic | sour & sour | Semi-automatic |
| PayGo | stru | Distributed | Proprietary model | Union | Automatic | sour & sour | Automatic |
| UDI | stru | Local | Proprietary model | Merge | Automatic | sour & sour, sour & inte | Automatic |
| Roomba | — | — | Universal model | Union | Automatic | sour & sour | Automatic |
| Quarry | semi | Local | Universal model | Union | Automatic | — | — |
| Cimple | stru | Distributed | Proprietary model | Merge | Manual | sour & sour, sour & inte | Semi-automatic |
| CopyCat | stru, semi | Distributed | Proprietary model | Union | Semi-automatic | sour & sour | Semi-automatic |
| Octopus | stru, semi | Distributed | Proprietary model | Merge | Semi-automatic | sour & inte | Semi-automatic |
Table 5
The comparison of MatVDS and other dataspace systems in the use phase.
| Prototype system | User interest and behaviour | Load | Query type | Query result |
|---|---|---|---|---|
| MatVDS | Consider the user interests and behaviour habits | Pre-integrated, and dynamic evolution | Keyword query, structured query, visualisation query | Union |
| OrientSpace | Consider the behaviour characteristics and habits | Dynamic evolution | Keyword query, structured query | Union |
| SEMEX | Does not consider | Run-time integration | Keyword query, structured query | Merge |
| iMeMex | Does not consider | Run-time integration | Keyword query, structured query | Union |
| PayGo | Does not consider | Run-time integration | Keyword query | Union |
| UDI | Does not consider | Run-time integration | Structured query | Merge |
| Roomba | Does not consider | Pre-integrated | Keyword query, structured query | Merge |
| Quarry | Does not consider | Run-time integration | Structured query | Union |
| Cimple | Does not consider | Run-time integration | Keyword query, structured query | Merge |
| CopyCat | Does not consider | Pre-integrated | Visualisation query | Union |
| Octopus | Does not consider | Pre-integrated | Keyword query | Merge |
Evolution is the most important problem to be solved in dataspace research. It is also the main basis for measuring the practicability of dataspace systems. Table 6 illustrates the comparison of MatVDS and other dataspace systems from the aspect of evolution. Compared with other dataspace systems, MatVDS has two types of feedback mechanisms, and makes the user requirement the centre of focus; thus, VDS realised dynamic evolution in the process of schema matching and mapping.
Table 6
The evolutionary comparison of MatVDS and other dataspace systems.
| Prototype system | Use output | Evolution method | Evolution processing |
|---|---|---|---|
| MatVDS | Sort results, browsing, sources | A variety of user feedback instances, explicit and implicit | Matching and mapping, the user requirement model |
| OrientSpace | Sort results, browsing, sources | User behaviour, implicit | Core dataspace, task space, associated information |
| SEMEX | Results, browsing | — | — |
| iMeMex | Results, browsing, sources | — | — |
| PayGo | Sort results | User feedback, explicit | Sorting query results |
| UDI | Sort results | — | — |
| Roomba | Results | User feedback, explicit | Matching |
| Quarry | Results, browsing | User feedback, explicit | Matching |
| Cimple | Sort results, browsing | User feedback, explicit | Matching |
| CopyCat | Results, sources | User feedback, explicit | Integration mode, mapping |
| Octopus | Results | User feedback, explicit | Integration mode, mapping |
5.2 Case study in Materials Scientific Data Services
A “Materials Scientific Data Sharing Service Platform” is constructed, as Materials Virtual DataSpace (MatVDS) (Figure 4) to implement intelligent service applications in the field of materials engineering. This platform integrated the massive, distributed and heterogeneous data resources under twelve categories: material basis, non-ferrous & alloy materials, ferrous materials, composite materials, organic polymer materials, inorganic non-metallic materials, information materials, energy materials, biomedical materials, natural materials & products, building materials, and road traffic materials.
The system architecture of MatVDS.
MatVDS has the characteristics of “Data as a Service, DaaS”, virtualisation processing, high-quality services, scalability, high reliability, and so on. It collected in total nearly 500,000 data resource items and continues to grow rapidly. The global semantic view of MatVDS has been built based on the domain core concepts and hierarchical structure in the field of materials engineering. This includes materials data from various perspectives, such as the materials categories, the basic features, the organisational structure, the chemical composition, the processing technology, the application performance, and so on.
Relationships of the users, data services and subjects are described by MatVDS. A specific dataspace is built for every user according to their requirements, which includes user preferences, data of interest and semantic relations of big materials scientific data.
The diversified and personalised intelligent services are achieved by the VDS model based on its evolution in the field of materials engineering (see Figure 5). Intelligent retrieval is the core and basis of these intellectualised data services. The flexible services are modularization in MatVDS based on the intelligent retrieval.
The collection of intelligent services in MatVDS.
Because of the semantic extraction, relevant knowledge and data sets are provided to users that may interested in. For example, the Figure 6 shows the results of the semantic search for query “corrosion-resistance”. One result shows “GB/T 18982-2003”, which belongs to the ferrous materials category, and stored as a “pdf” file. The result of “X2CrTi12” belongs to the ferrous materials category, and stored in both semi-structured data XML files and non-structured data chart files. While the result of “EVA” belongs to the energy materials category, which stored in databases as table files. “Furan resin” belongs to the organic polymer material category and stored as image files. Therefore, it proves that we could quickly and accurately acquire the relevant data services based on the domain knowledge.
The demand-oriented data service instance in MatVDS.
6 Conclusions and Future Work
This paper proposed the model of VDS for materials scientific big data management, sharing and services in the field of materials engineering. The conceptual model and theories are introduced for the dataspace model.
And the automatic construction is also described to implement the VDS model. The VDS could also be evolved automatically to adopt the changing requirements of the users and service demands. Comparisons with other dataspace models are shown in the experimental results. And MatVDS is implemented for supporting intelligent services in materials engineering field. The results shows the efficiency of the model in applying intelligent services for the specific domain.
The future work of VDS includes improving the optimized method for automatic schema matching and mapping, developing better evolutionary algorithms for VDS evolution, and extending the scope of intelligent services in the field of materials engineering.